Open source software (OSS) has been widely used in both free and proprietary applications. The Black Duck reports that 96% of their scanned applications contain open source components, which account for 57% of the code base on average. At the same time, vulnerabilities embedded in upstream OSS are fast propagated to the underlying applications. Also, the clone or reuse of OSS without explicit reference makes it challenging for maintainers to track and mitigate vulnerabilities. Our research develops practical techniques for detecting such vulnerabilities, which help build a more reliable and secure information system infrastructure.
Read more about our works:
GraphSPD
PatchDB
Security Patch Classification
Security Patch Identification
BinProv

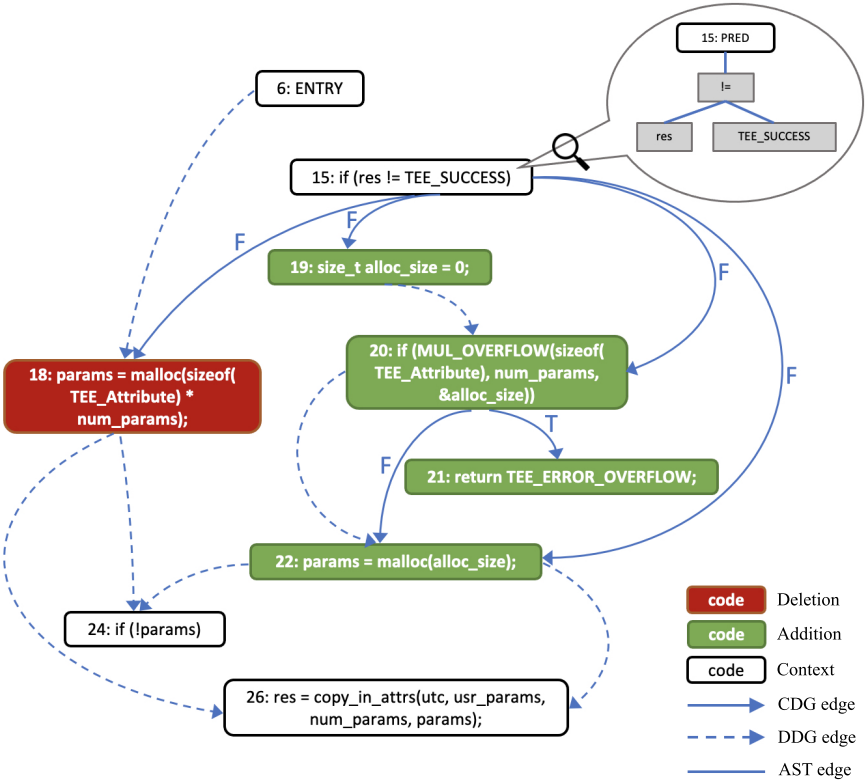
With the increasing popularity of open-source software, embedded vulnerabilities have been widely propagating to downstream software. Due to different maintenance policies, software vendors may silently release security patches without providing sufficient advisories (e.g., CVE). This leaves users unaware of security patches and provides attackers good chances to exploit unpatched vulnerabilities. Thus, detecting those silent security patches becomes imperative for secure software maintenance. In our paper, we propose a graph neural network based security patch detection system named GraphSPD, which represents patches as graphs with richer semantics and utilizes a patch-tailored graph model for detection. We first develop a novel graph structure called PatchCPG to represent software patches by merging two code property graphs (CPGs) for the pre-patch and post-patch source code as well as retaining the context, deleted, and added components for the patch. By applying a slicing technique, we retain the most relevant context and reduce the size of PatchCPG. Then, we develop the first end-to-end deep learning model called PatchGNN to determine if a patch is security-related directly from its graphstructured PatchCPG. PatchGNN includes a new embedding process to convert PatchCPG into a numeric format and a new multi-attributed graph convolution mechanism to adapt diverse relationships in PatchCPG.
Published in the 44th IEEE Symposium on Security and Privacy (S&P) 2023.
Download the Paper Code Website Export Citation
@INPROCEEDINGS{GraphSPD23Wang,
author={Wang, Shu and Wang, Xinda and Sun, Kun and Jajodia, Sushil and Wang, Haining and Li, Qi},
booktitle={2023 IEEE Symposium on Security and Privacy (SP)},
title={GraphSPD: Graph-Based Security Patch Detection with Enriched Code Semantics},
year={2023},
pages={604-621},
doi={10.1109/SP46215.2023.00035}
}
Provenance identification, which is essential for binary analysis, aims to uncover the specific compiler and configuration used for generating the executable. Traditionally, the existing solutions extract syntactic, structural, and semantic features from disassembled programs and employ machine learning techniques to identify the compilation provenance of binaries. However, their effectiveness heavily relies on disassembly tools (e.g., IDA Pro) and tedious feature engineering, since it is challenging to obtain accurate assembly code, particularly, from the stripped or obfuscated binaries. In addition, the features in machine learning approaches are manually selected based on the domain knowledge of one specific architecture, which cannot be applied to other architectures. In this paper, we develop an end-to-end provenance identification system BinProv, which leverages a BERT (Bidirectional Encoder Representations from Transformers) based embedding model to learn and represent the context semantics and syntax directly from the binary code. Therefore, BinProv avoids the disassembling step and manual feature selection in provenance identification. Moreover, BinProv can distinguish the compilers and the four optimization levels (O0/O1/O2/O3) by fine-tuning the classifier model with the embedding inputs for specific provenance identification tasks. Experimental results show that BinProv achieves 92.14%, 99.4%, and 99.8% accuracy at byte sequence, function, and binary levels, respectively. We further demonstrate that BinProv works well on obfuscated binary code, suggesting that BinProv is a viable approach to remarkably mitigate the disassembler dependence in future provenance identification tasks. Finally, our case studies show that BinProv can better identify compiler helper functions and improve the performance of binary code similarity detection.

Publiched in the International Symposium on Research in Attacks, Intrusions and Defenses (RAID), 2022.
Download the Paper Code Export Citation
@inproceedings{xu2022binprov,
author = {He, Xu and Wang, Shu and Xing, Yunlong and Feng, Pengbin and Wang, Haining and Li, Qi and Chen, Songqing and Sun, Kun},
title = {BinProv: Binary Code Provenance Identification without Disassembly},
year = {2022},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
booktitle = {Proceedings of the 25th International Symposium on Research in Attacks, Intrusions and Defenses},
pages = {350–363},
numpages = {14},
location = {Limassol, Cyprus},
series = {RAID '22}
}
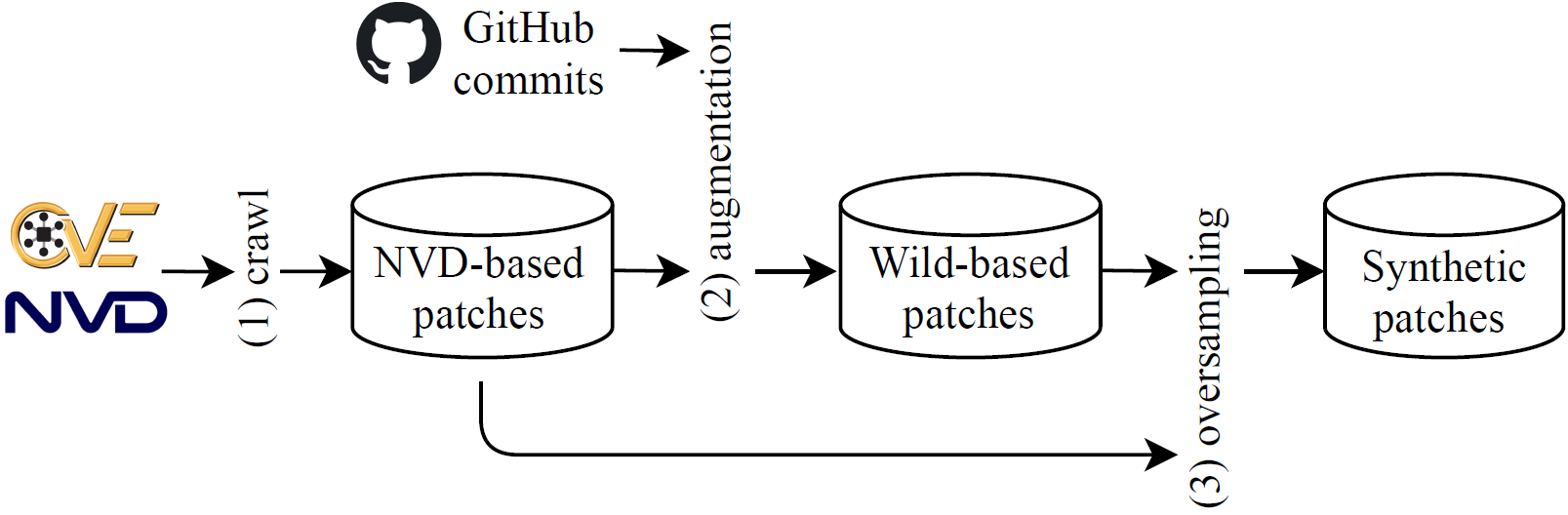
Security patches, embedding both vulnerable code and the corresponding fixes, are of great significance to vulnerability detection and software maintenance. A large patch dataset is critical for various patch analysis tasks. However, the existing patch datasets suffer from insufficient samples and low varieties. In this paper, we construct a large-scale patch dataset called PatchDB consisting of three datasets, namely, NVD-based dataset, wild-based dataset, and synthetic dataset. The NVD-based dataset is extracted from the patch hyperlinks indexed by the NVD. The wild-based dataset includes security patches that we collect from the commits on GitHub. To improve the efficiency of data collection and reduce the effort on manual verification, we develop a new nearest link search method to help find the most promising security patch candidates. Moreover, we provide a synthetic dataset, which uses a new oversampling method to synthesize patches at the source code level, enriching the control flow variants of original patches. We conduct a set of studies to investigate the effectiveness of the proposed algorithms and evaluate the properties of the collected dataset. The experimental results show that PatchDB can help improve the performance on security patch identification.
Publiched in the IEEE Conference on Dependable Systems and Networks (DSN) 2021.
Download the Paper Slides Dataset Code Website Export Citation
@INPROCEEDINGS{wang2021dsn,
author={X. {Wang} and S. {Wang} and P. {Feng} and K. {Sun} and S. {Jajodia}},
booktitle={2021 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN)},
title={PatchDB: A Large-Scale Security Patch Dataset},
year={2021},
volume={},
number={},
pages={},
doi={}
}
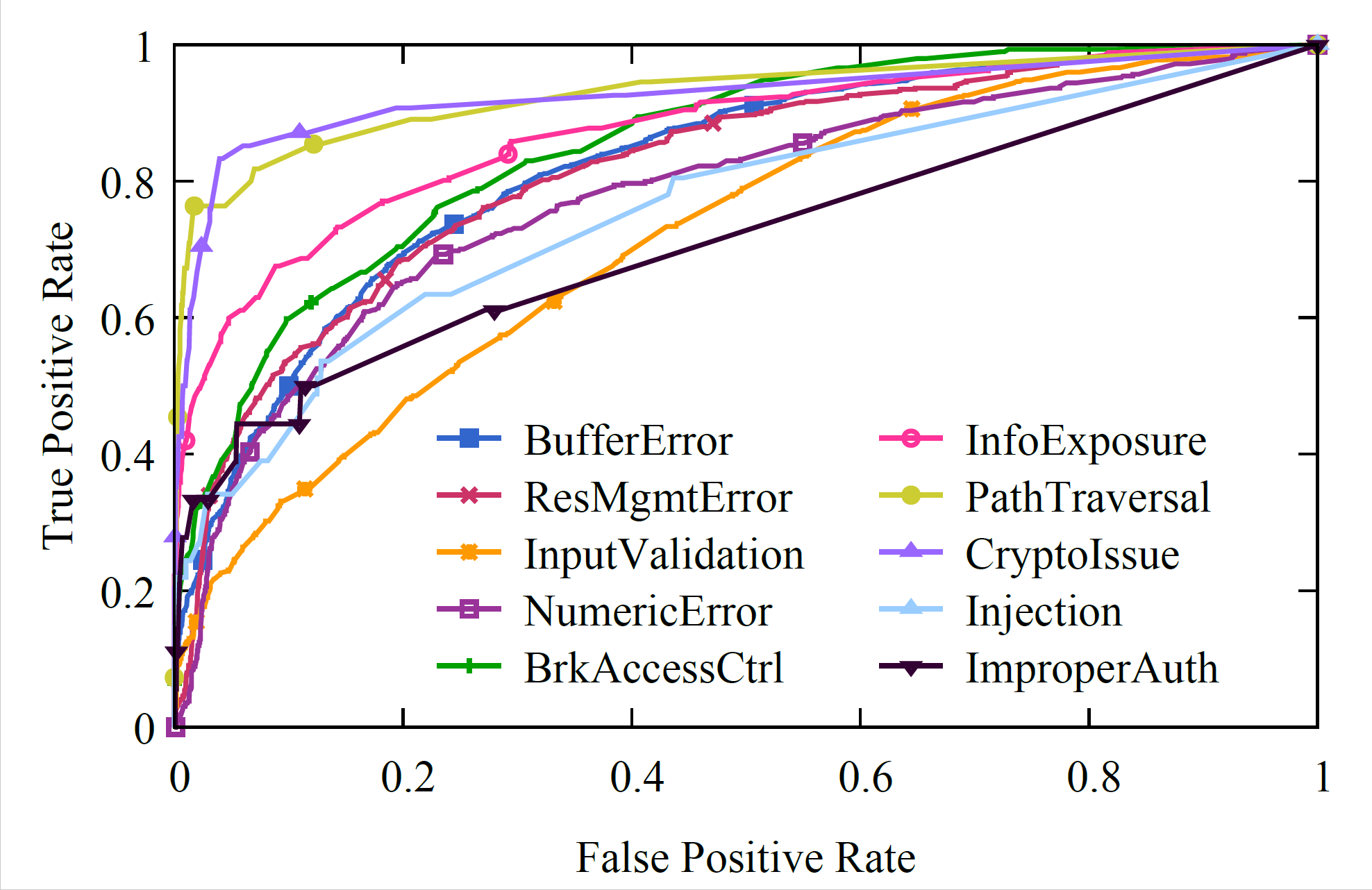
With the increasing usage of open source software (OSS) in both free and proprietary applications, vulnerabilities embedded in OSS are also propagated to the underlying applications. It is critical to find security patches to fix these vulnerabilities, especially those essential to reduce security risk. Unfortunately, given a security patch, currently, there does not exist a way to automatically recognize the vulnerability that is fixed. In our paper, we first conduct an empirical study on security patches by type (i.e., corresponding vulnerability type), using a large-scale dataset collected from the National Vulnerability Database (NVD). Based on analysis results, we develop a machine learning-based system to help identify the vulnerability type of a given security patch. The evaluation results show that our system achieves good performance.
Published in the IEEE Conference on Communications and Network Security (CNS) 2020.
Download the Paper Export Citation
@INPROCEEDINGS{wang2020cns,
author={X. {Wang} and S. {Wang} and K. {Sun} and A. {Batcheller} and S. {Jajodia}},
booktitle={2020 IEEE Conference on Communications and Network Security (CNS)},
title={A Machine Learning Approach to Classify Security Patches into Vulnerability Types},
year={2020},
volume={},
number={},
pages={1-9},
doi={10.1109/CNS48642.2020.9162237}
}
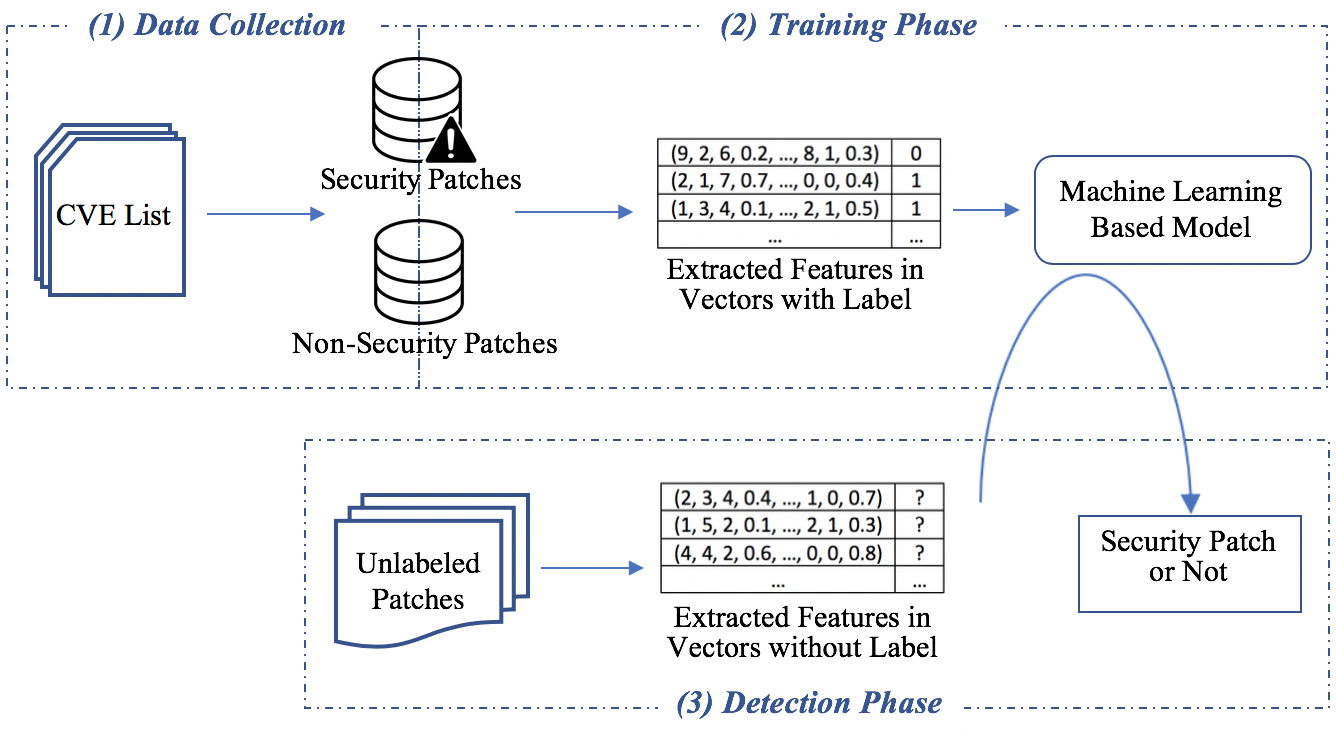
Security patches in open source software (OSS) not only provide security fixes to identified vulnerabilities but also make the vulnerable code public to the attackers. Therefore, armored attackers may misuse this information to launch N-day attacks on unpatched OSS versions. The best practice for preventing this type of N-day attacks is to keep upgrading the software to the latest version in no time. However, due to the concerns on reputation and easy software development management, software vendors may choose to secretly patch their vulnerabilities in a new version without reporting them to CVE or even providing any explicit description in their change logs. When those secretly patched vulnerabilities are being identified by armored attackers, they can be turned into powerful "0-day" attacks, which can be exploited to compromise not only unpatched version of the same software, but also similar types of OSS (e.g., SSL libraries) that may contain the same vulnerability due to code clone or similar design/implementation logic. Therefore, it is critical to identify secret security patches.
In our paper, we develop a defense system and implement a toolset to automatically identify secret security patches in OSS. To distinguish security patches from other patches, we first build a security patch database that contains more than 4700 security patches mapping to the records in the CVE list. Next, we identify a set of features to help distinguish security patches from non-security ones using machine learning approaches. Finally, we use code clone identification mechanisms to discover similar patches or vulnerabilities in similar types of OSS. The experimental results show our approach can achieve good detection performance. A case study on OpenSSL, LibreSSL, and BoringSSL discover 12 secret security patches.
Publiched in the IEEE Conference on Dependable Systems and Networks (DSN) 2019.
Download the Paper Dataset Export Citation
@INPROCEEDINGS{wang2019dsn,
author={X. {Wang} and K. {Sun} and A. {Batcheller} and S. {Jajodia}},
booktitle={2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN)},
title={Detecting "0-Day" Vulnerability: An Empirical Study of Secret Security Patch in OSS},
year={2019},
volume={},
number={},
pages={485-492},
doi={10.1109/DSN.2019.00056}
}